自注意力机制
自注意力机制
problems
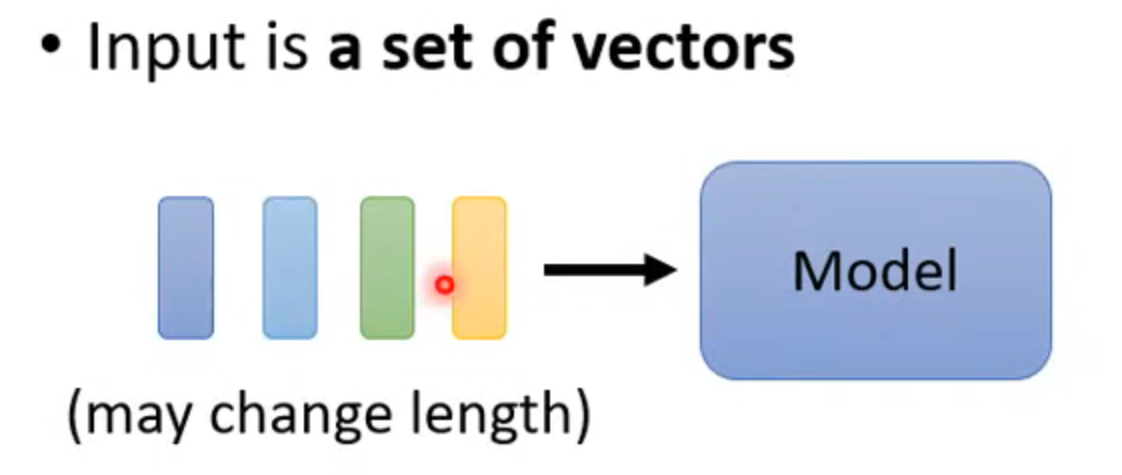
输入可能会很复杂,不只是一个vector而是一组vector,比如语言识别,输入很多单词,每一个句子都是一排长度不一的向量组
解决方法
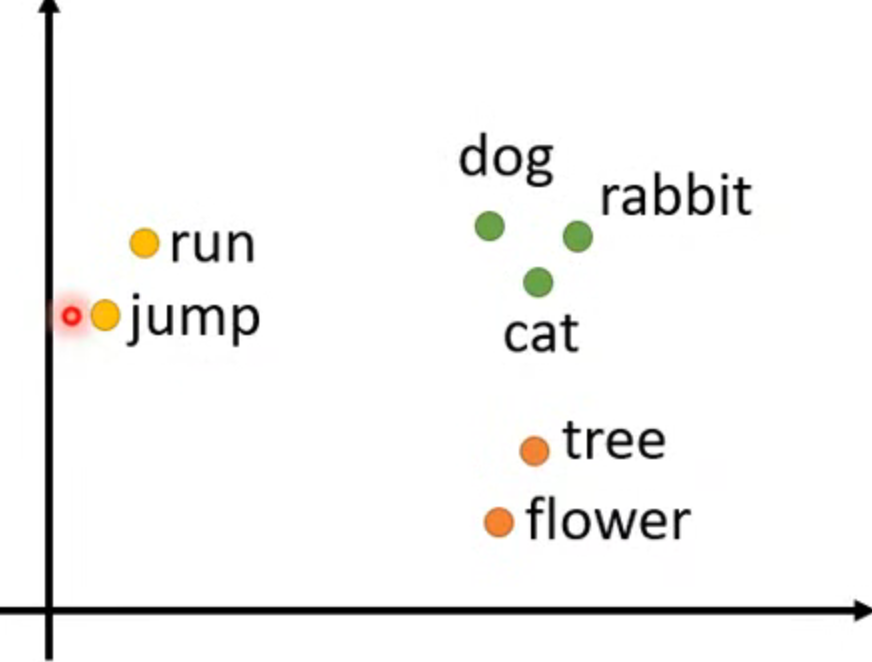
- one-hot encoding 独热编码:每一个单词都对应一个单独的编码

- word embedding 每一个词汇一个向量,向量有次序
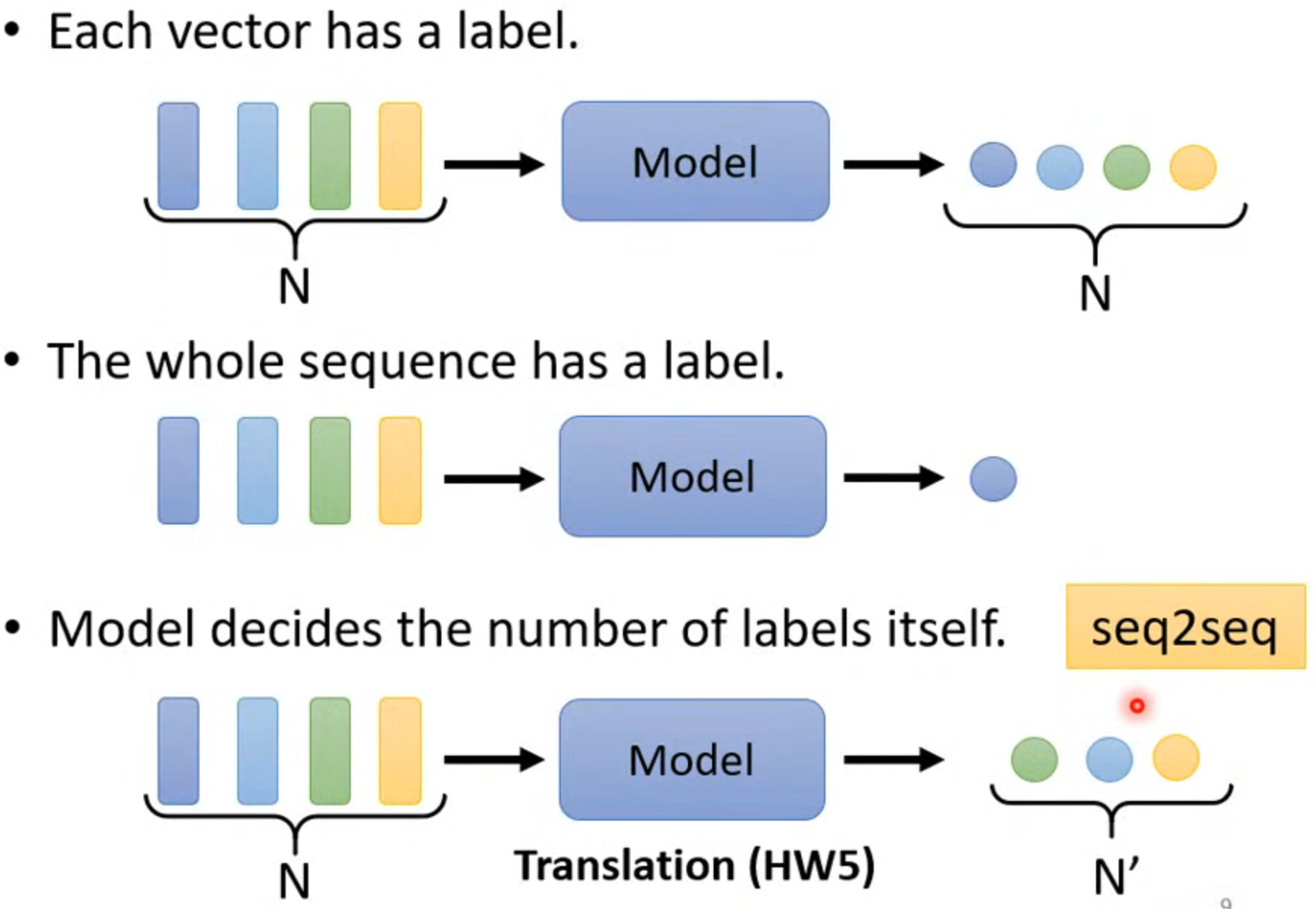
输出同样有很多情况,输入n个,输出n个,或者只输出1个,或者不知道要输出几个(翻译)
self-attention
此讲只考虑输入和输出数量相同的情况
sequence labeling
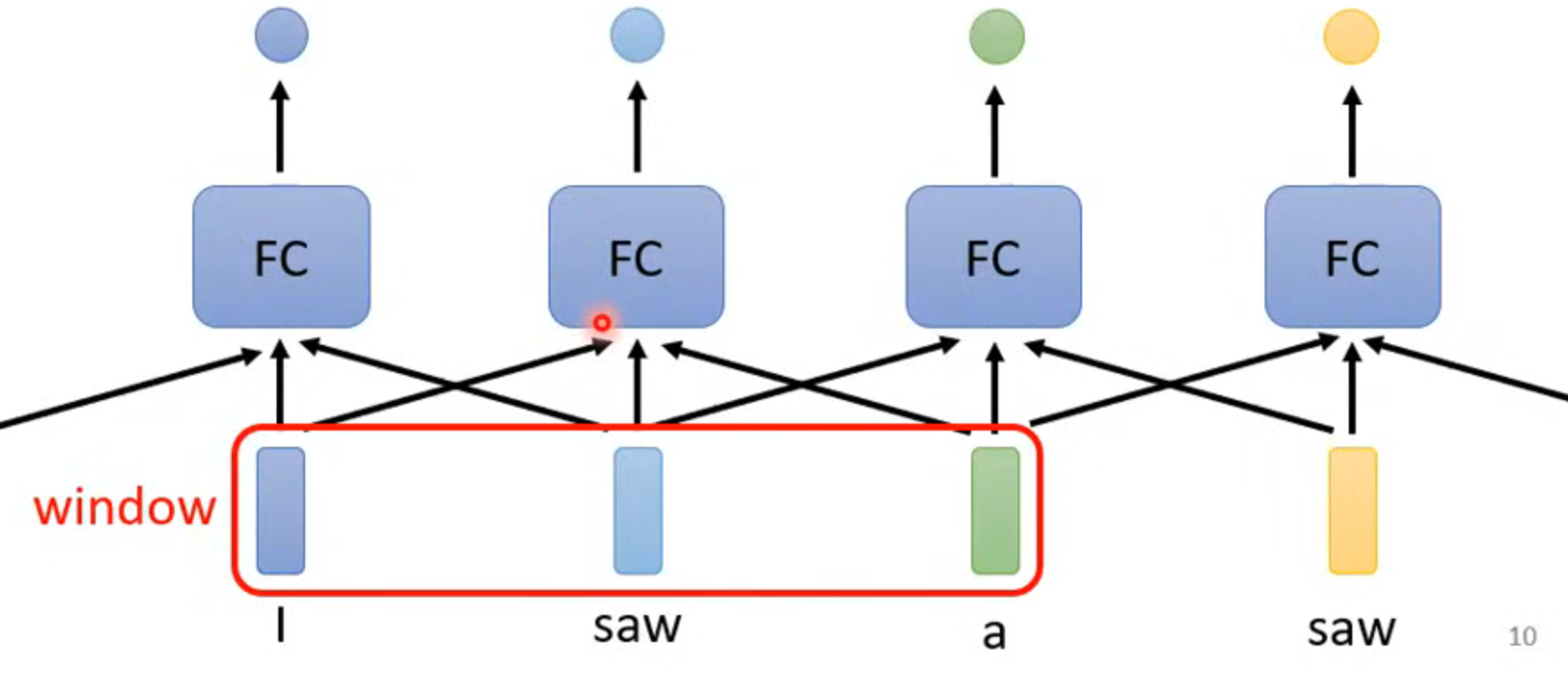
按照之前的做法讲一个window中几个连续的输入传到一个FC(fully connected network)中,不能确定一个合适的window的大小,并且每一个输入的长度都不一样,不可取
self-attention
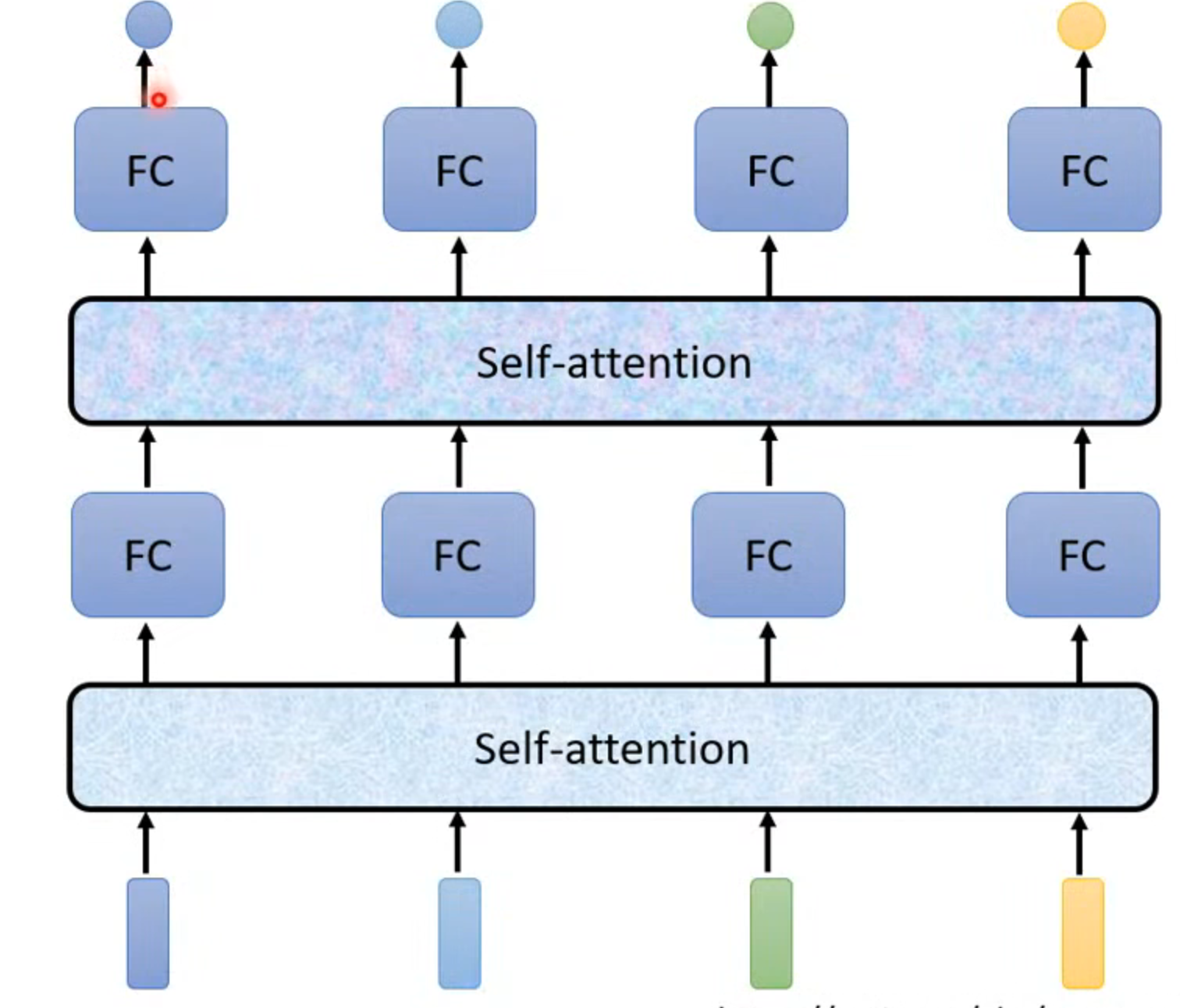
考虑整个sequence后经过self-attention新的输出作为输入传入FC,此过程可以叠加
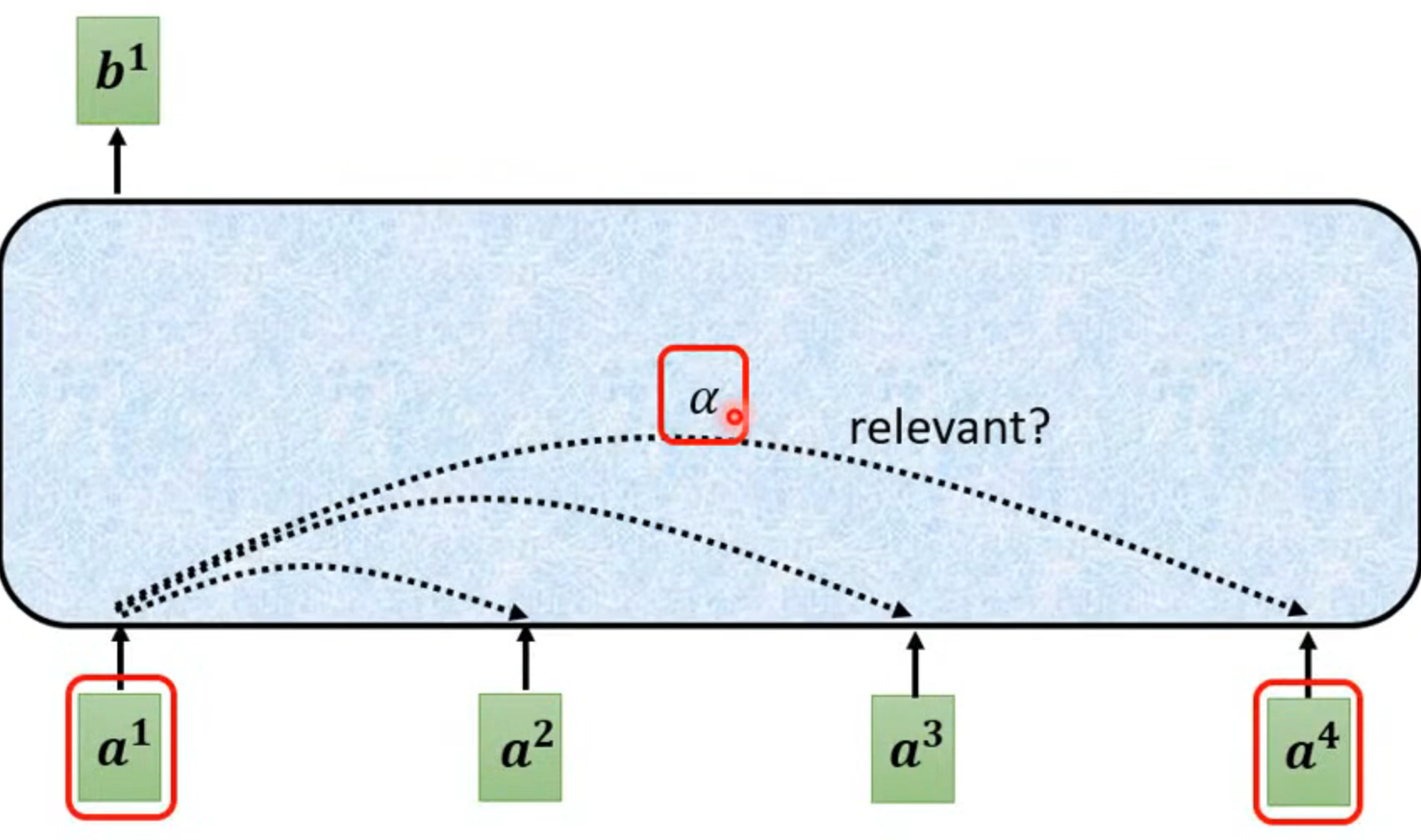
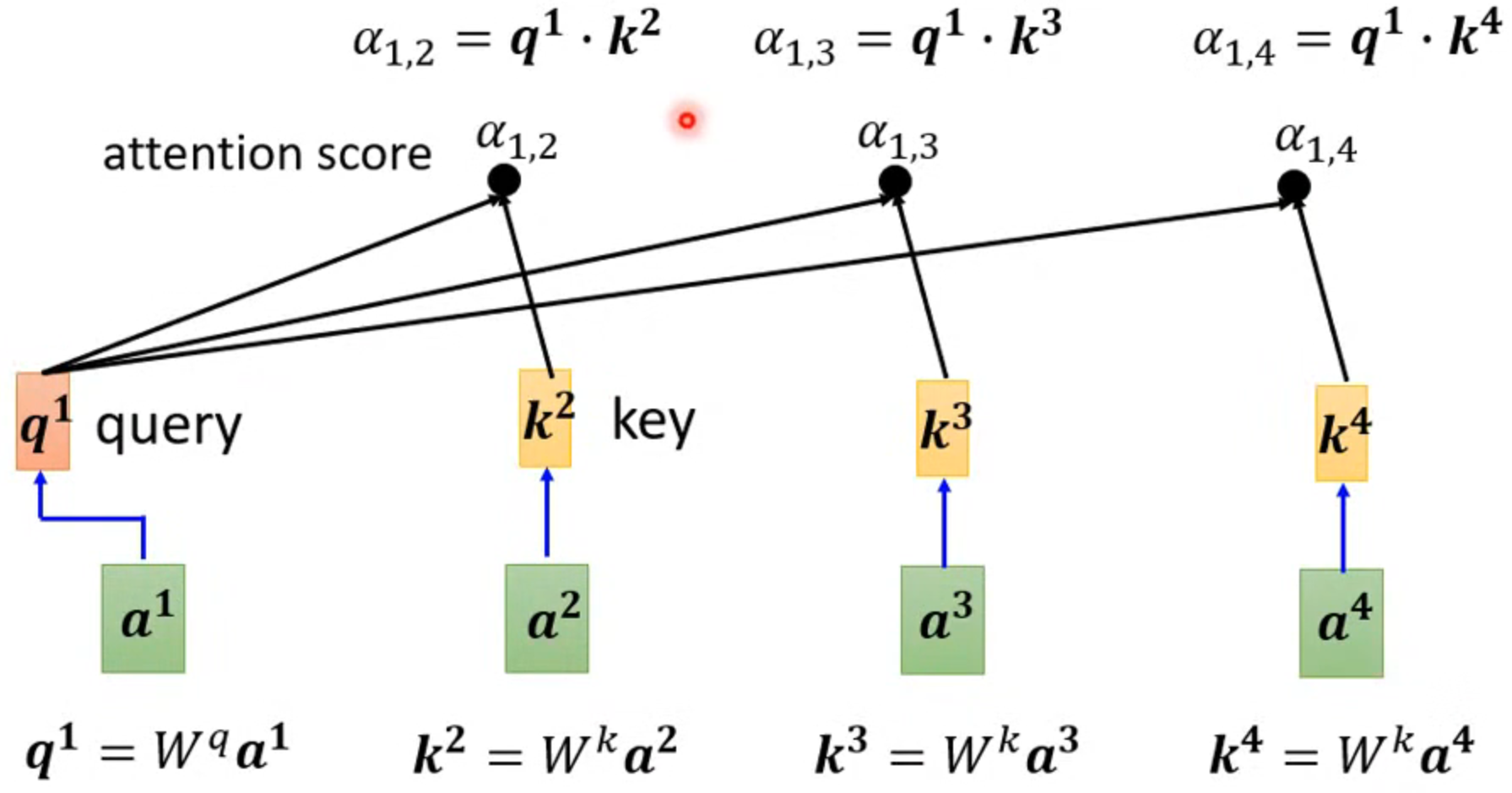
- 以输出b1为例,首先需要判断各个输入值的相关性
判断方法采用dot-product
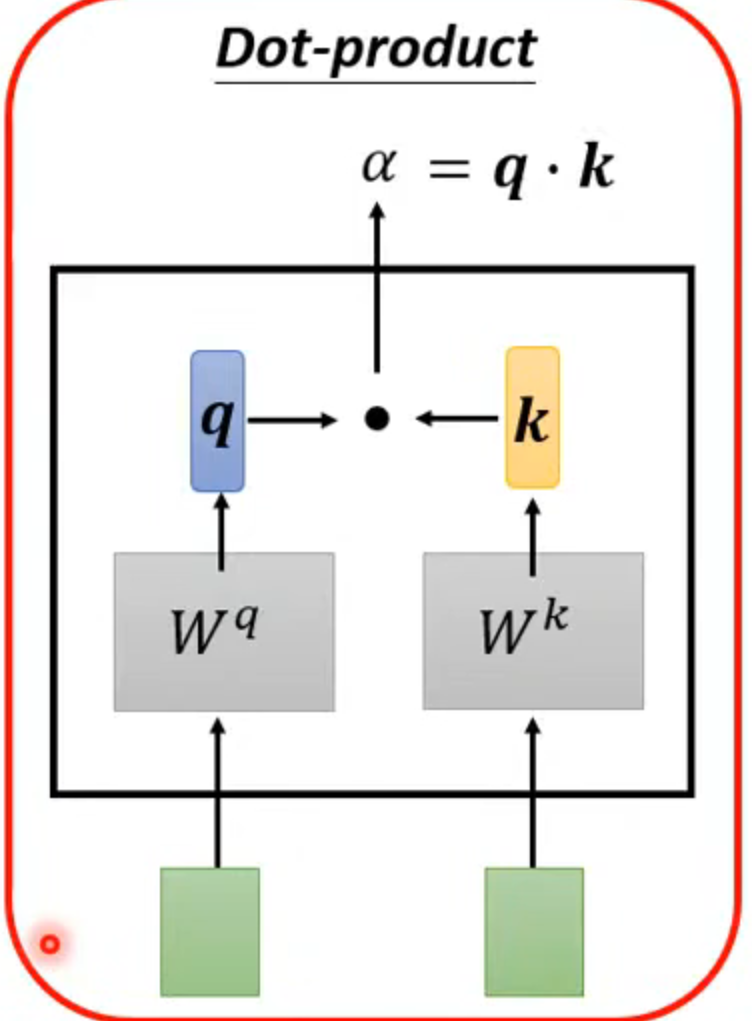
操作过程
然后计算v,谁的alpha大,哪个输入就主导输出b
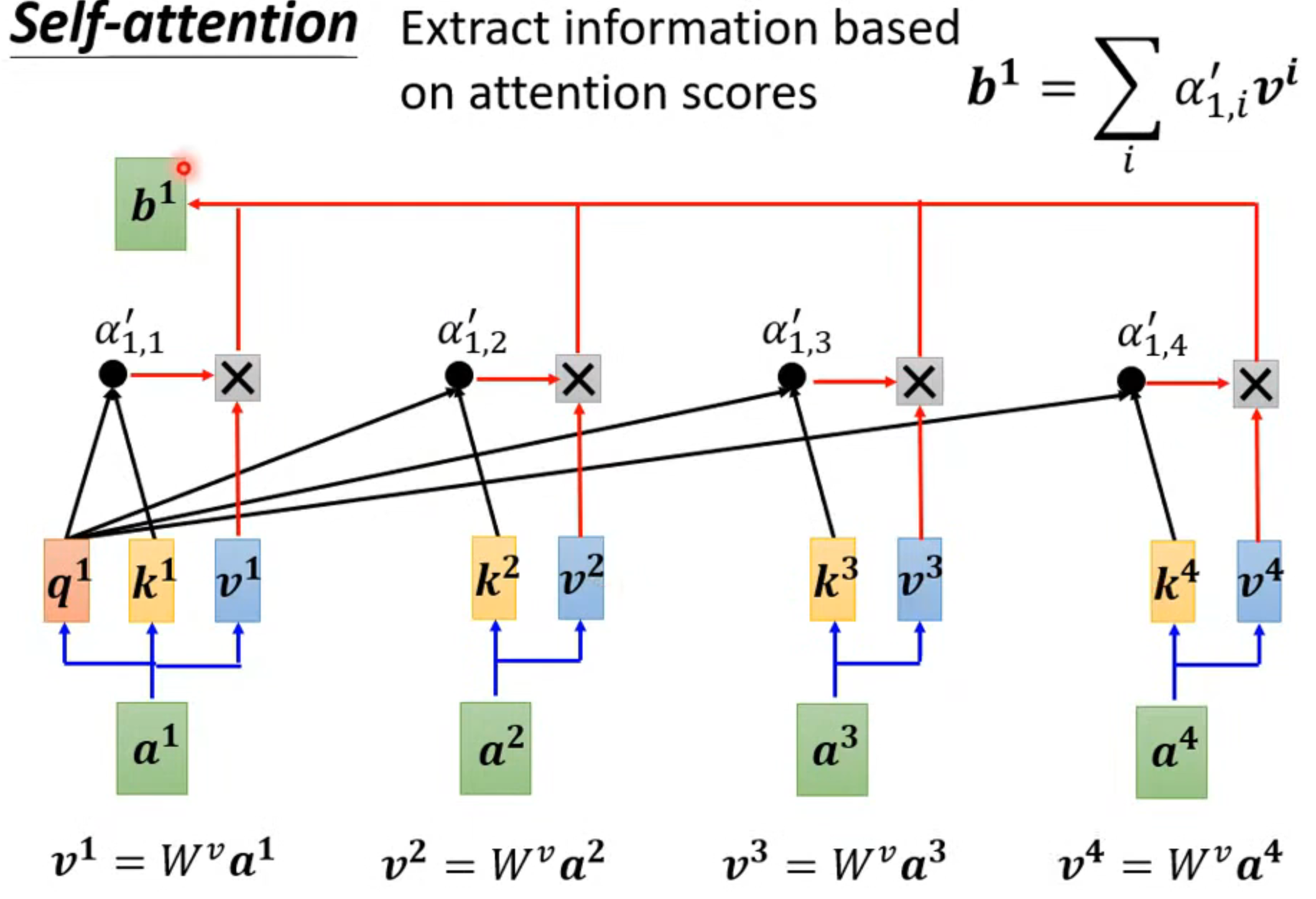
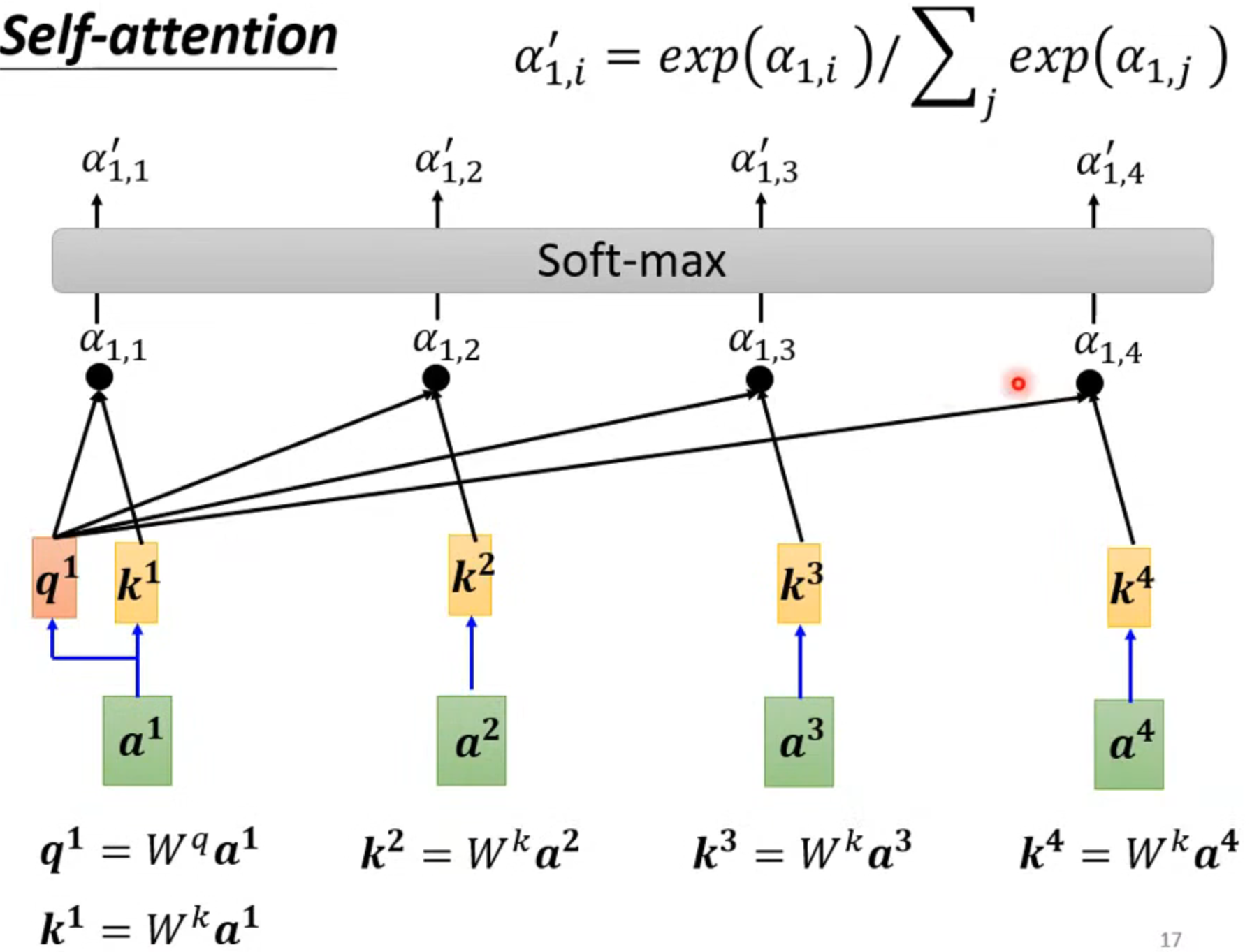
实际也需要自己和自己计算关联性,然后一般再经过softmax
使用矩阵简化合并相同的计算
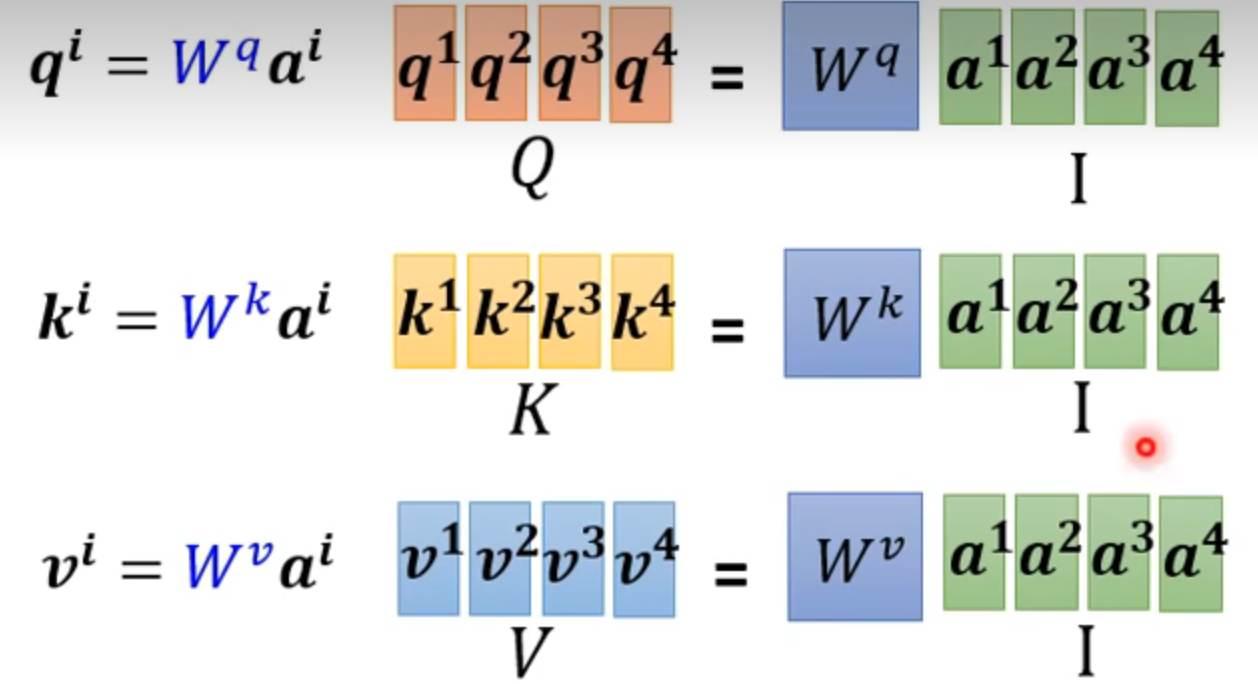

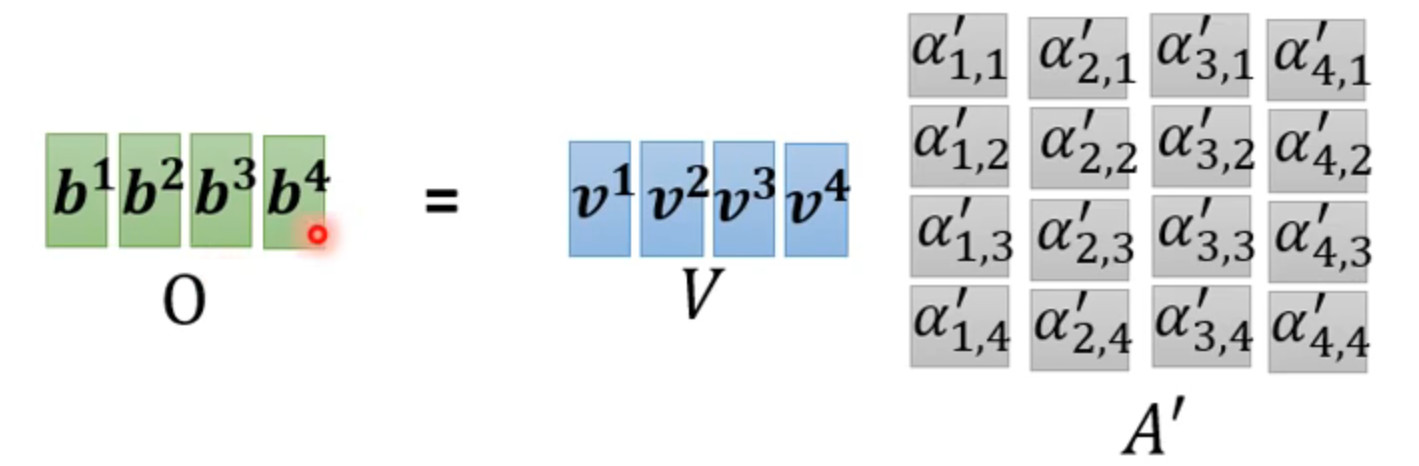
矩阵O就是输出,A‘ 就是attention matrix,只有wq,wk,wv是参数需要学习
multi-head self-attention另一种进阶方法,对q,k,v再乘矩阵,产生更多的参数,计算更多领域的相关性
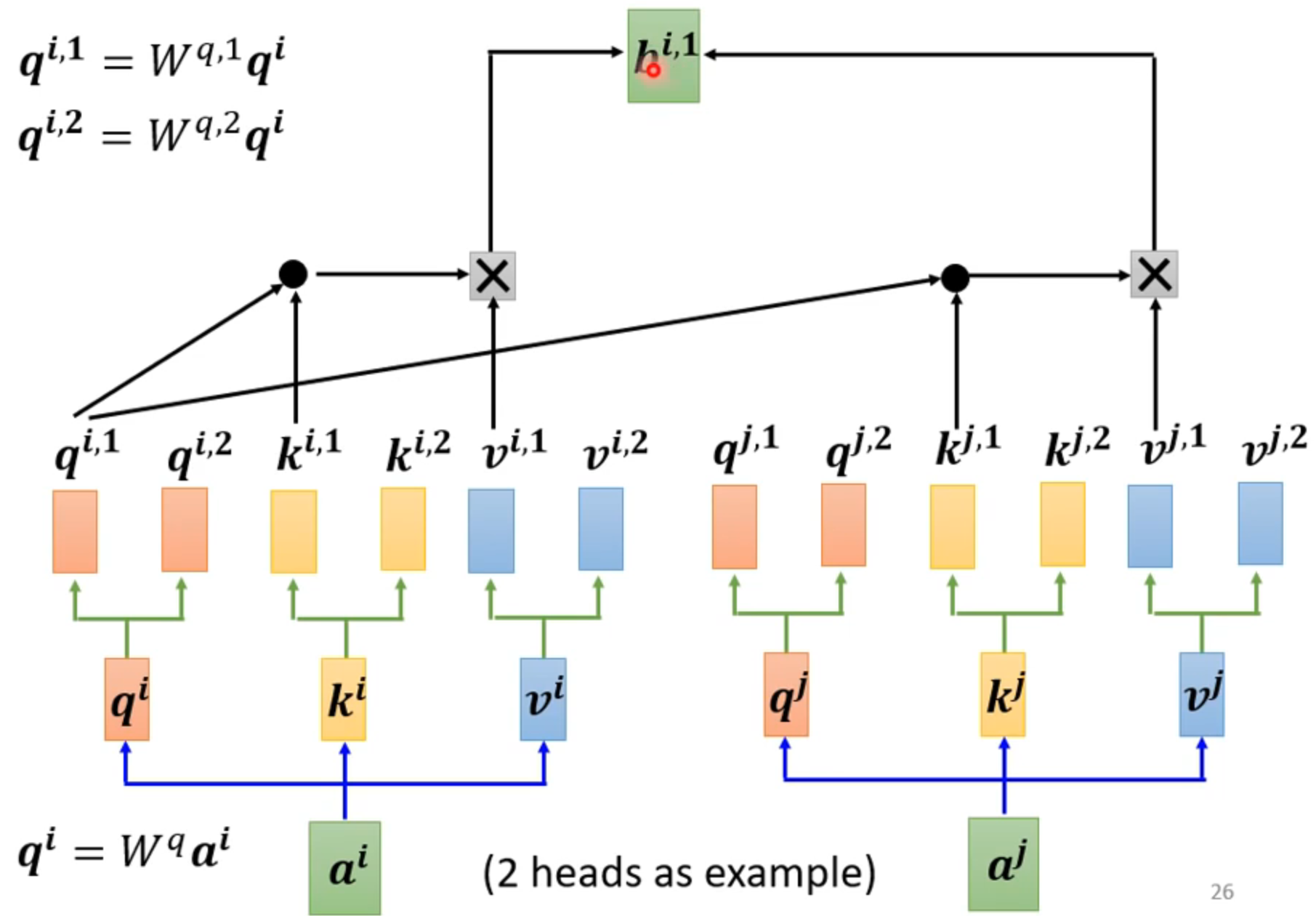
计算出输出后乘矩阵进行合并

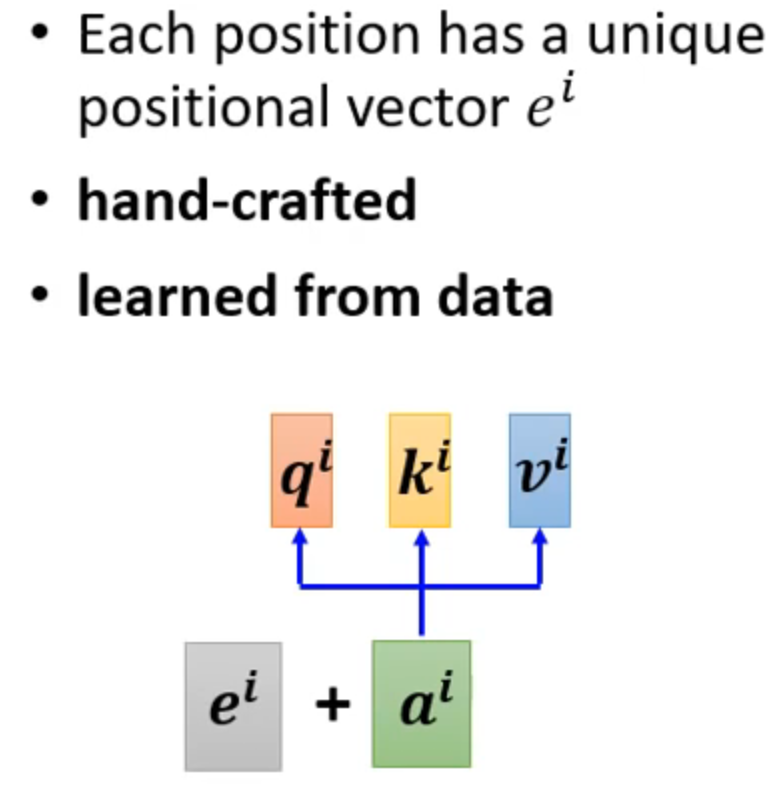
positional encoding :上述过程没有考虑词汇的位置,此方法会考虑
other application
for speech
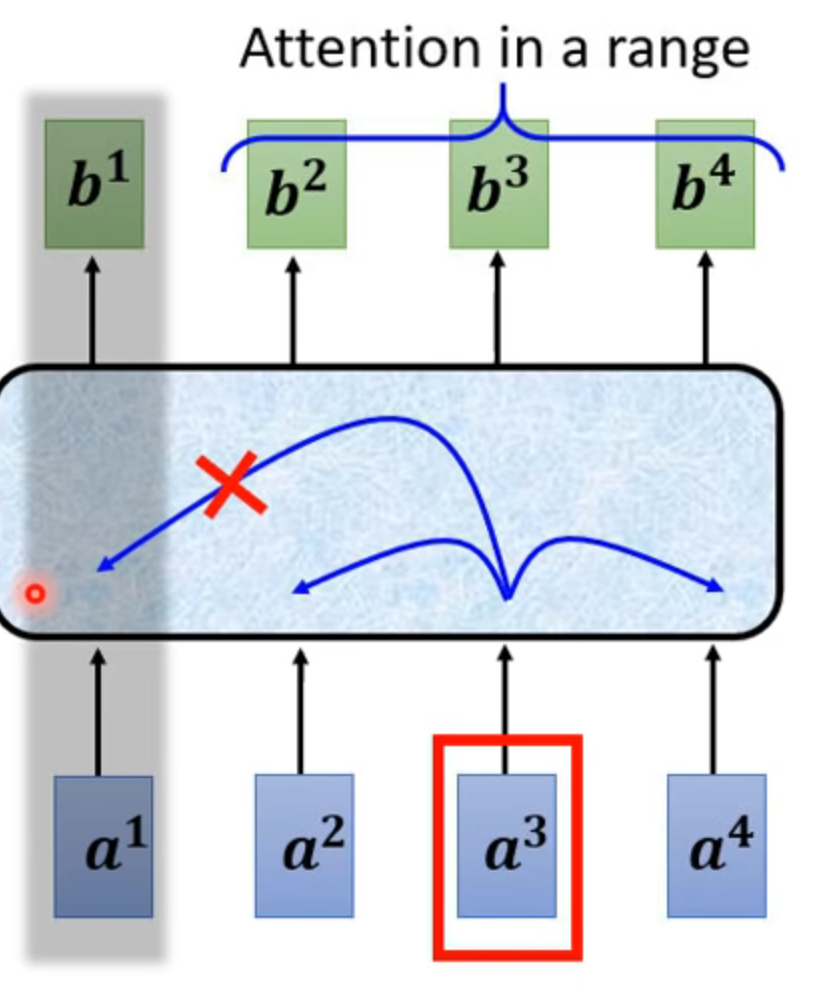
truncated self-attention
语音数据太大,只考虑部分相连的输入
for image

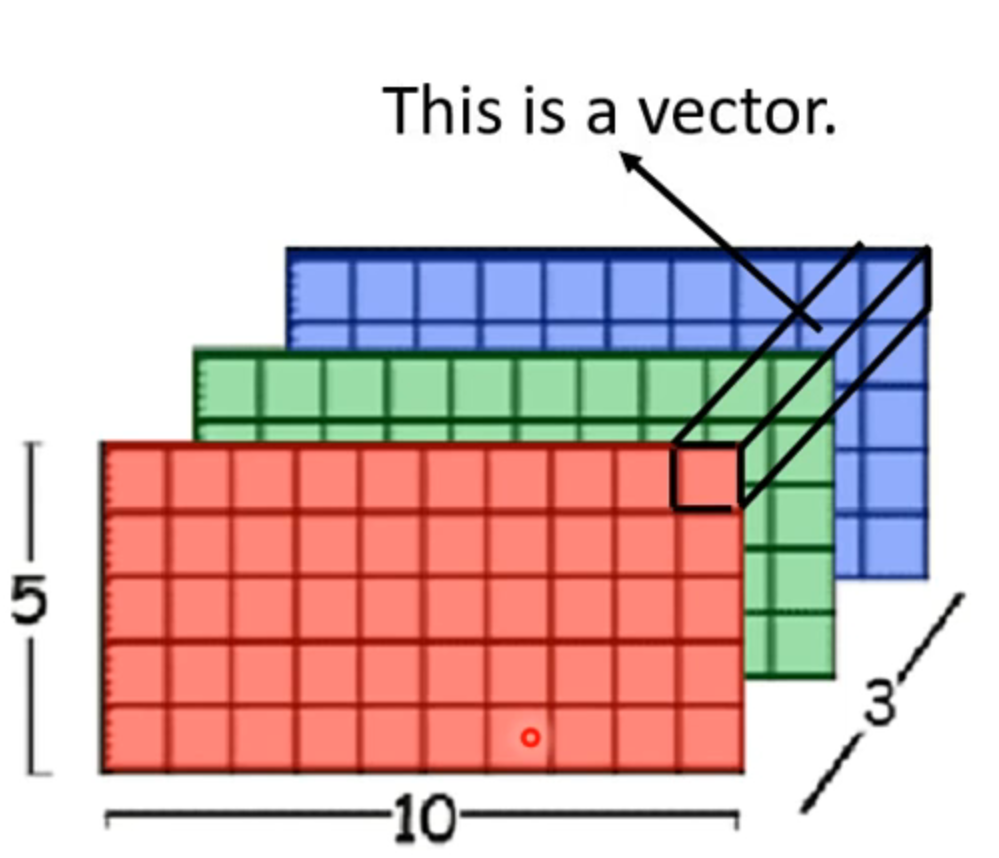
不把整个看成一个很长的向量,而是每一个像素的三个channel合在一起为一个vector
整张图是很多vector
for graph 只考虑连通节点之间的关系
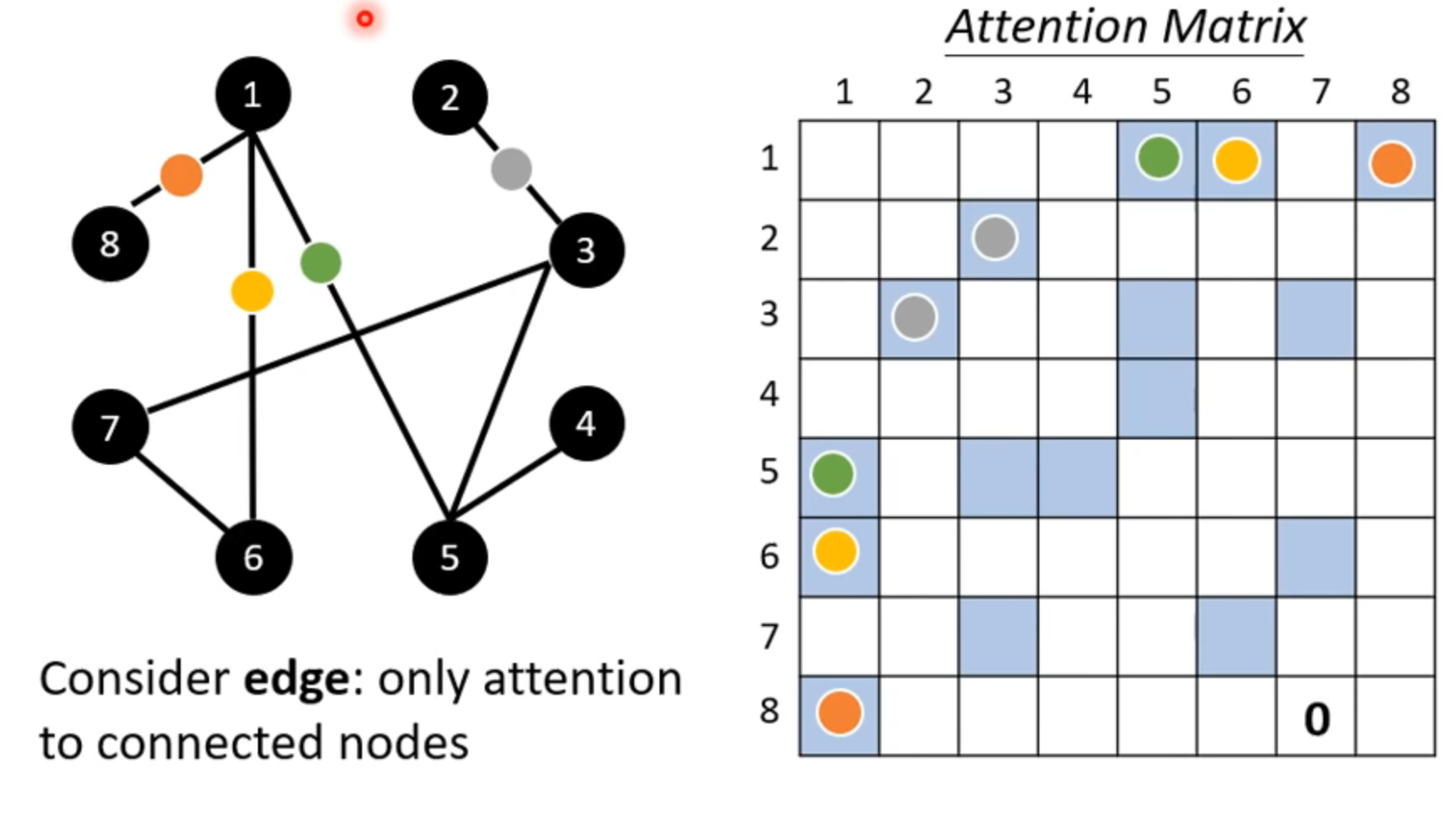
这就是一种 graph neural network(GNN)
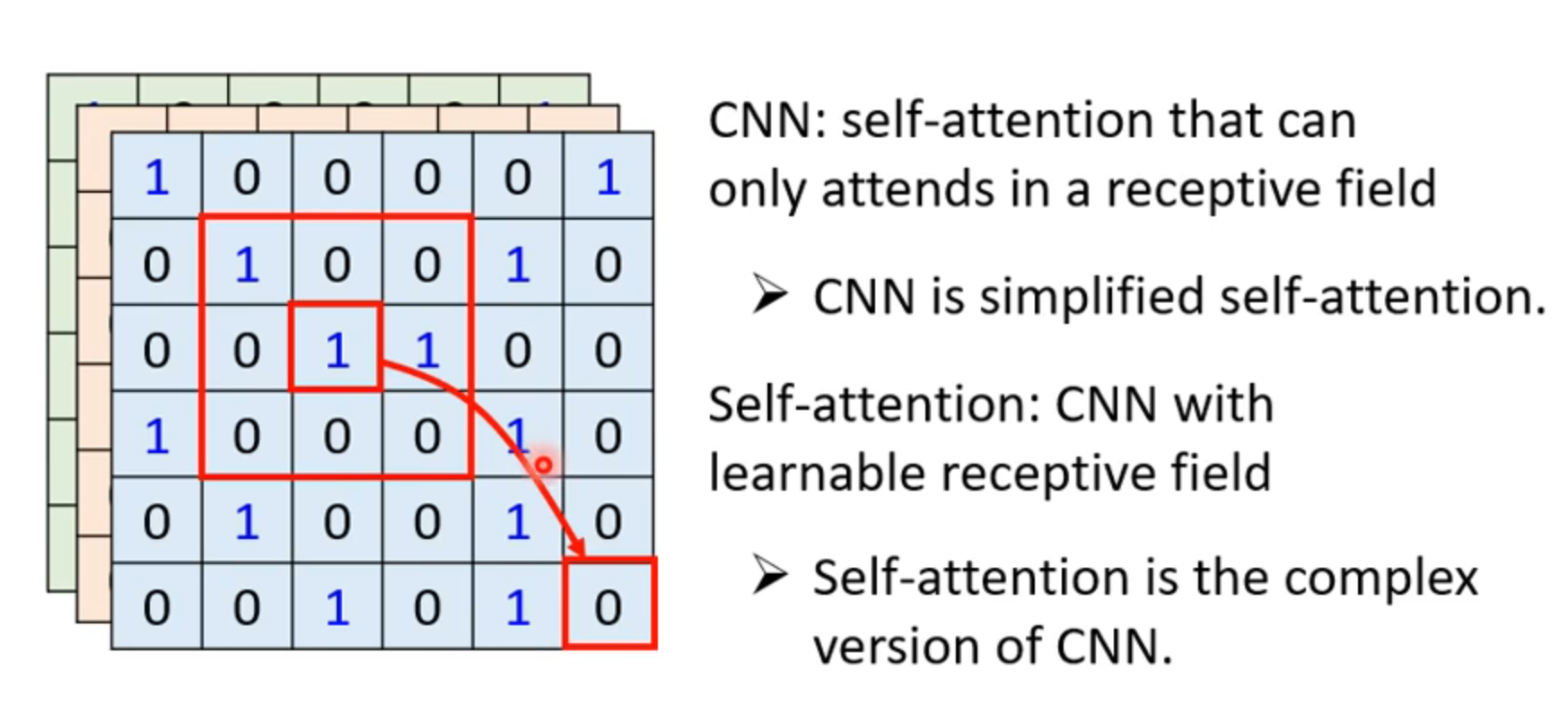
self-attention VS CNN

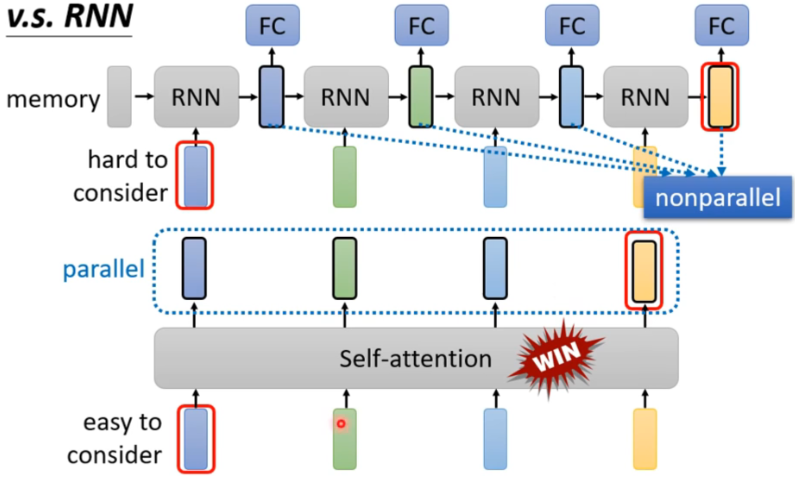
self-attention VS RNN